피파온라인 댓글 감성분석 프로젝트 전처리 및 EDA Part.1
댓글과 같은 텍스트 데이터를 처리하는 즉, 자연어를 처리하는 NLP는 실생활에서 매우 유용하게 사용될 수 있다. 이번 프로젝트에서는 평소에 즐겨하던 게임이었던 피파온라인4의 선수 댓글을 감성 분석하고 사용자가 선택한 선수와 비슷한 선수를 추천하는 추천 시스템을 개발했다.
먼저, 데이터를 수집하고 딥러닝 모델을 위한 데이터 전처리 과정을 정리해보자.
Comments Sentiment Analysis 프로젝트 전처리 및 EDA Part.1
1. 데이터 수집
감성분석을 위해 필요한 댓글 데이터는 피파 인벤이라고 하는 피파 온라인의 선수 정보가 담겨 있는 홈페이지에서 크롤링 했다.
import pandas as pd
import numpy as np
import requests
from requests.exceptions import HTTPError
from bs4 import BeautifulSoup
수집할 데이터는 사용자 ID, 선수 이름, 포지션, 댓글, 평점이다. 빈 DataFrame을 만들고 크롤링한 데이터를 이 DataFrame에 병합할 것이다.
DATA_PATH = '.............'
#크롤링 데이터 병합을 위해 빈 DataFrame 생성
df = pd.DataFrame(columns = ['userId', 'player_name', 'position', 'comment', 'rating'])
편의상 골키퍼를 제외하고 공격수, 미드필더, 수비수 포지션의 데이터를 각각 7만개 정도씩 총 21만개의 데이터를 수집하는 것을 목표로 크롤링을 진행했다. 밑의 함수는 시작 페이지와 포지션을 입력받아 데이터를 수집하고 수집된 데이터를 위에서 만든 빈 데이터프레임과 병합시키는 함수이다.
def crawling_func(pages, position):
global df
try:
while pages <= 3800:
url = f'.......{pages}&formation=' + position
req = requests.get(url)
soup = BeautifulSoup(req.content, 'html.parser')
comment = soup.find_all(class_ = 'fifa4 comment')
player_name = soup.find_all(class_ = 'fifa4 name')
rating = soup.find_all(class_ = 'fifa4 rate')
user_name = soup.find_all(class_ = 'text_right')
for i in range(len(user_name)):
user_id = user_name[i].get_text().split()[0]
p_name = player_name[i].get_text()
cm = comment[i].get_text()
r = rating[i].get_text()
df = pd.concat([df, pd.DataFrame([[user_id,p_name, position ,cm, r]], columns = df.columns)])
df.reset_index(inplace = True, drop = True)
pages += 1
if pages % 50 == 0:
print(pages) # 100 pages 마다 출력
except:
pass
df.to_csv(f'{DATA_PATH}fifa_comment_data_{position}.csv', index = False)
return df
공격수 댓글 데이터 가져오기
df_fw = crawling_func(1,'fw')
print(df_fw.shape)
display(df_fw.tail())

미드필더 댓글 데이터 가져오기
df_mf = crawling_func(1,'mf')
print(df_mf.shape)
df_mf.tail()

수비수 댓글 데이터 가져오기
df_df = crawling_func(1843,'df')
print(df_df.shape)
df_df.head()

데이터 중복확인 및 제거
df_all = pd.concat([df_fw,df_mf,df_df], axis = 0)
print(df_all.duplicated().sum())
df_all.drop_duplicates(inplace = True)
df_all.reset_index(inplace = True, drop = True)
df_all.shape

중복값과 결측치 확인
print(df_all.duplicated().sum())
print(df_all.isnull().sum())

데이터 저장
df_all.to_csv(f'{DATA_PATH}fifa_comment_data.csv', index = False)
2. 필요없는 단어 제거
선수를 스탯으로만 평가해야하는데 선수거래와 관련된 댓글이 달려있고 평점을 아무 기준 없이 매기는 사용자들이 꽤 많다. 따라서, 분석에 도움이 되지 않는 거래 관련 단어나 특수문자 등의 불필요한 단어를 제거했다.
df_all = pd.read_csv(f'{DATA_PATH}fifa_comment_data.csv')
df_all.tail()

거래 관련 댓글 제외. 거래와 관련된 댓글이 포함되어 있으면 1 아니면 0.
df_all['card'] = [1 if '사가주세요' in s or '팔아주세요' in s or '사주세요' in s or '삽니다' in s or '사요' in s or '팝니다' in s
or '팔아요' in s or '쪽지' in s or '구합니다' in s or '카톡' in s else 0 for s in df_all.comment]
display(df_all.loc[df_all.card == 1].tail(10)) # 거래 관련 댓글
display(df_all.loc[df_all.card == 0].tail(10)) # 거래와 관련없는 댓글

거래와 관련 없는 데이터만 사용하기
df_all = df_all.loc[df_all.card == 0].reset_index(drop = True)
df_all.shape```
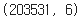{: .align-center}
<br>
<br>
영어, 숫자, 한글 이외에 불필요한 특수문자 제거
```python
df_all['comment'] = df_all['comment'].str.replace('[^0-9a-zA-Zㄱ-ㅎㅏ-ㅣ가-힣 ]','')
df_all.tail()
df_all[['userId', 'player_name', 'position', 'comment', 'rating']].to_csv(f'{DATA_PATH}fifa_comment_data2.csv', index = False)

데이터를 수집하고 거래 관련 단어, 불필요한 특수 문자 등을 제거한 전처리를 진행했다. 다음 포스팅에서는 KNU 감성사전을 사용하여 각 댓글마다 감성 점수를 도출하고, 감성 점수를 기반으로 해당 댓글이 긍정인지 부정인지를 나타내는 타겟변수를 만드는 과정을 정리해보겠다.