Note 432 Segmentaion, Object Detection/Recognition
MLP나 CNN을 이용하면 이미지에 맞는 class를 예측하는 이미지 분류를 할 수 있다. 하지만, MLP는 공간정보를 보존하지 못하고, CNN 또한 완전 연결 신경망 층에서는 기존에 추출했던 공간정보를 보존하지 못하기 때문에 더 세부적인 이미지 분류가 어렵다. 이번 포스팅에서는 이미지를 이미지가 아닌 픽셀 단위로 처리해서 더 세부적인 분류가 가능하게 하는 분할과 객체 탐지/인식에 대해 정리해보자.
분할(Segmentation)
Segmentation은 아래의 그림과 같이 하나의 이미지에서 같은 의미를 가지고 있는 부분을 구분해내는 작업이다. 자율주행이나 위성 및 항공 사진 등의 분야에서 많이 사용된다. CNN을 사용한 기존의 이미지 분류는 이미지 단위로 데이터를 처리해서 해당 이미지 전체가 어떤 class에 속하는지 예측했다. Segmentation은 이미지 단위가 아니라 이미지를 이루고 있는 픽셀 단위에서 데이터를 처리해서 더 세부적인 분류가 가능해진다. 동일한 의미를 가지고 있는 픽셀들마다 labeling이 되어있고(사람, 자동차, 건물 등) 이 픽셀의 label이 무엇인지 예측하는 것이다.

이미지출처: https://medium.com/intro-to-artificial-intelligence/semantic-segmentation-udaitys-self-driving-car-engineer-nanodegree-c01eb6eaf9d
Semantic Segmentation vs (Semantic) Instance Segmentation
Semantic Segmentation은 위의 그림처럼 동일한 의미를 갖는 객체는(사람, 자동차, 도로) 모두 동일하게 라벨링 한다(자동차는 모두 파란색, 사람은 모두 빨간색). 이를 의미가 같은 객체는 동일한 라벨로 분류한다고 하여 의미적 분할(Semantic Segmentation)이라고 한다.

이미지출처: https://www.analyticsvidhya.com/blog/2019/04/introduction-image-segmentation-techniques-python/
반면 Instance Segmentation은 위의 그림과 같이 동일한 의미를 가진 객체라도 따로 labeling 한다. 같은 사람이어도 다른 색으로, 같은 자동차라도 다른 색으로 표현된 것을 알 수 있다.
FCN(Fully Convolutional Networks)과 U-net
동일한 의미를 갖는 객체는 동일하게 labeling 해주는 Semantic Segmentation의 대표적인 모델로는 FCN과 U-net이 있다. FCN과 U-net 모델을 알아보기 전에 Upsampling과 Downsampling의 개념부터 정리해보자.
- Upsampling
Downsampling은 CNN에서 사용되는 것처럼 Convolution과 Pooling을 사용하여 이미지의 특징을 추출하는 과정이다. 이미지 분할의 최종 목표는 픽셀 단위로 labeling을 하는 것이기 때문에 Downsampling을 통해 줄어든 이미지의 크기를 원래의 이미지와 비슷한 크기로 다시 키워야하고 이 과정을 Upsampling이라고 한다.
Upsampling에서는 기존의 Convolution과는 다른 Transpose Convolution이 적용되는데 Transpose Convolution을 했다고 해서 원래 이미지의 값을 똑같이 복원하는 것은 아니다. 단순히, 이미지의 차원만 동일하게 맞추는 것이 목적이다. Transpose Convolution에서 이미지의 차원을 증가시키는 것 역시 커널을 사용하고, padding과 stride도 사용되어 이미지의 차원을 증가시킨다. Transpose Convolution에서 이미지의 차원이 증가되는 과정은 다음과 같다.

1) 새로운 parameter인 $ z $ 와 $ p’ $ 을 계산한다.
\[z = s - 1, p' = k - p - 1, s' = 1\]2) input의 각 행과 열 사이에 z 만큼의 0을 넣는다.
3) 변형된 input에 p’만큼 패딩을 해준다.
4) 변형된 input에 주어진 strides 만큼 커널과 합성곱을 수행한다.
위의 그림을 예시로 들면 downsampling 후 output은 4 x 4 행렬이고, upsampling에서 이를 input으로 사용할 것이다. z는 위 예제에서 downsampling 단계에서 stride를 4로 했다고 가정했기때문에 z가 3이되어서 원래 input 사이에 3개의 0이 들어가게 되고, p’ = 3-1-1 이라서 테두리 바깥쪽으로 1칸씩만 0을 삽입한다. 또한 s’은 1로 고정시켜주었기 때문에 커널을 1칸씩 이동하면서 합성곱을 수행하고 upsampling의 최종 출력벡터를 만들어낸다. Upsampling은 downsampling처럼 여러번 수행되어 output 행렬을 변환시킬 수 있다.
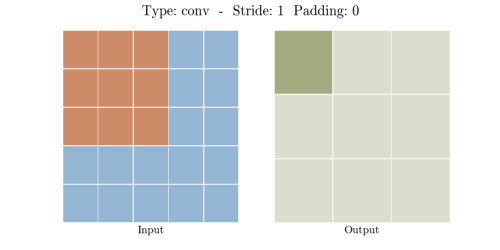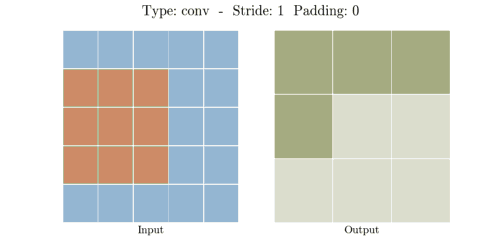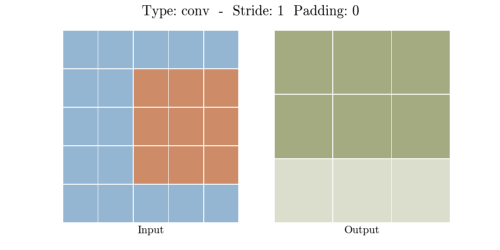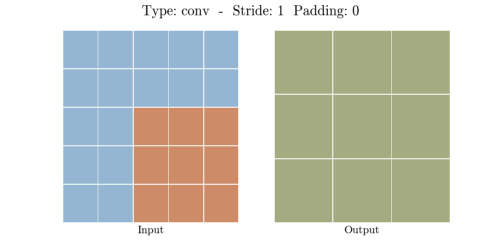
다음은 다양한 stride와 padding의 예시이다.
- Stride: 1, Padding: 0
- Stride: 2, Padding: 0

- Stride: 1, Padding: 1
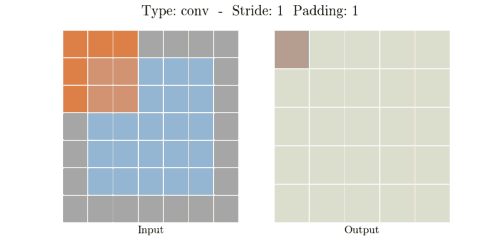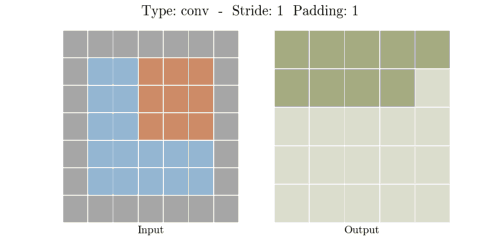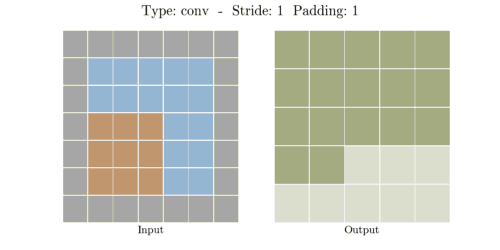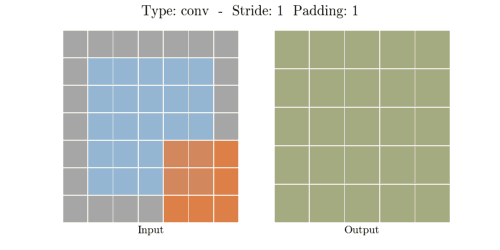
- Stride: 2, Padding: 1
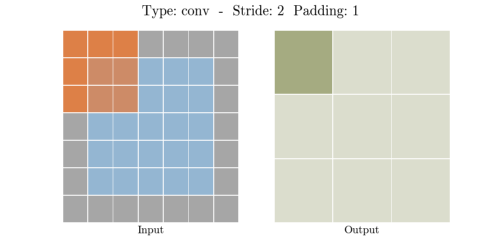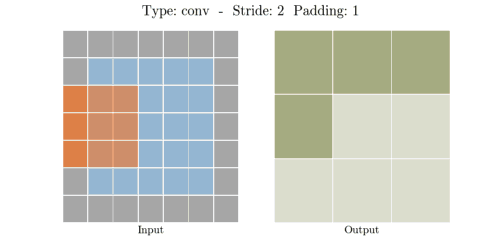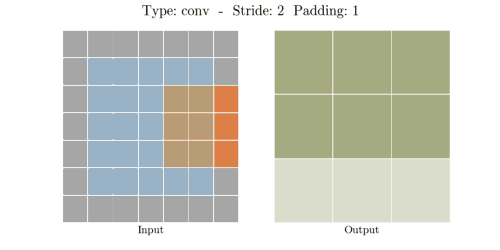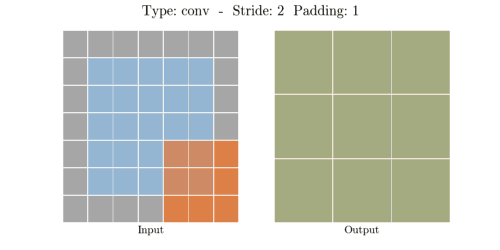
이미지출처: https://velog.io/@hayaseleu/Transposed-Convolutional-Layer%EC%9D%80-%EB%AC%B4%EC%97%87%EC%9D%B8%EA%B0%80
- FCN
먼저 FCN은 CNN의 완전 연결 신경망에서 공간정보가 무시되는 단점을 보완하여 완전 연결 신경망 층까지 합성곱 층으로 대체한 모델이다. 이미지를 픽셀 단위로 labeling 하기 위해서는 어떤 층에 있더라도 위치 정보가 보존되어야하기 때문에 완전 연결 신경망을 합성곱 층으로 대체한 방법을 사용한다.

이미지출처: https://gaussian37.github.io/vision-segmentation-fcn/
위의 그림과 같이 FCN은 이미지 데이터를 입력 받아서 CNN의 합성곱층 처럼 downsampling을 수행한 뒤 이 결과에 upsampling을 수행해 다시 이미지의 크기를 키운다.
!작동원리는 추후에 추가하자
- U-net
U-net도 이미지 분할에 자주 사용되는 모델 중 하나이다. U 형태로 되어있는 그림에서 왼쪽은 downsampling, 오른쪽은 upsampling의 과정을 나타낸다. U-net은 합성곱 연산 후 각 층에서 도출된 특성 맵의 일부를 적절히 잘라내어 각각의 upsampling 수행시에 입력되는 데이터와 병합해서 사용하므로 위치 정보를 최대한 보존하려고 한다. 추가로 왼쪽처럼 downsampling을 수행하는 지점을 인코더, 오른쪽처럼 upsampling을 수행하는 지점을 디코더라고 부르기도 한다.

이미지출처: Source:- https://arxiv.org/abs/1505.04597
그림에서 마지막에 있는 2는 클래스의 수이다. 그 전의 수는 채널 수와 사이즈로 이루어져있다.
!작동원리는 추후에 추가하자
객체 탐지/인식(Object Detection/Recognition)
객체 탐지/인식은 전체 이미지에서 label과 일치하는 객체를 찾아내는 작업이다. Segmentation과 함께 자율주행을 위한 주요 인공지능 기술이다. 객체의 경계에 Bounding Box라고 하는 사각형 박스를 만들고, 박스 내의 객체가 어떤 class에 속하는지 분류하는 작업이다. 또한, 박스 내의 이미지는 하나의 객체라고 판단하기 때문에 굳이 픽셀 단위로 분류하지 않고 이미지 단위로 분류한다는 특징이 있다.

이미지출처: https://diy-project.tistory.com/124
- IoU(Intersection over Union)
객체 탐지의 평가지표를 IoU라고 한다. 아래 그림과 같이 파란색 박스가 정답 박스고, 빨간색 박스가 객체를 예측한 박스이다. 즉, 빨간색 박스 내의 범위의 객체가 강아지라고 인식한 것이다.

이미지출처: https://debuggercafe.com/evaluation-metrics-for-object-detection/
IoU는 다음과 같은 공식으로 계산된다. 분자는 실제 객체의 범위와 예측 객체의 범위가 겹치는 정도이고, 분모는 겹친 두 범위의 전체이다. 즉, 예측이 실제 범위와 비슷한 크기로 객체를 인식하고 실제 객체의 박스와 많이 겹쳐있을수록 IoU의 값이 높은 것이다. 따라서 예측 범위를 넓게해서 무조건 많이 겹치게 한다고 IoU값이 높은 것이 아니다.



이미지출처: https://pyimagesearch.com/2016/11/07/intersection-over-union-iou-for-object-detection/
대표적인 객체 탐지 Model
어떤 단계를 거쳐 분류가 진행되는지에 따라 2-stage와 1-stage 방식으로 모델의 종류를 나눌 수 있다.
- Two Stage Detector
Two Stage Detector는 알고리즘을 통해 객체가 있을 만한 곳을 추천 받은 뒤에 추천 받은 Region에 대해 분류를 수행한다. 객체가 있을 만한 곳을 추천해주는 stage를 Region Proposal 이라고 하고, 추천 받은 region을 RoI(Region of Interest)라고 한다. 대표적인 2-stage model로는 R-CNN계열의 모델들이 있다. one stage에 비해 비교적 느리지만 두 가지 단계를 거치기 때문에 정확하다는 장점을 가지고 있다.
ex) R-CNN, Fast R-CNN, Faster R-CNN 등

- One Stage Detector
One stage detector는 특정 지역을 추천받는 단계가 따로 존재하지 않고, 입력된 이미지를 Grid와 같은 작은 공간으로 나누고 해당 공간을 탐색하며 분류를 수행하는 과정이 한 단계에서 이루어진다. 대표적인 모델로는 SSD(Single Shot multibox Detector), YOLO(You Only Look Once) 등이 있고, 한가지 단계만을 거치기 때문에 2-stage detector에 비해 부정확하지만 빠르다는 장점이 있다.

이미지출처: https://hoya012.github.io/blog/Tutorials-of-Object-Detection-Using-Deep-Learning-first-object-detection-using-deep-learning/